
Roozbeh Mottaghi
Senior Tech Lead
Meta Fundamental AI Research (FAIR) - Robotics
Email: roozbehm [at( gmail.com



Senior Tech Lead
Meta Fundamental AI Research (FAIR) - Robotics
Email: roozbehm [at( gmail.com
I am a Senior AI Research Scientist Manager at FAIR and an Affiliate Associate Professor in Paul G. Allen School of Computer Science & Engineering at the University of Washington.
Prior to joining FAIR, I was the Research Manager of the PRIOR team at the Allen Institute for AI. Before that, I was a Postdoctoral Researcher in the Computer Science Department at Stanford University. I received a Ph.D. in Computer Science from UCLA, advised by Alan Yuille. I obtained my Masters degrees from Simon Fraser University and Georgia Institute of Technology and my Bachelors degree from Sharif University of Technology.
I have had the pleasure of working with the following students, Pre-doctoral Young Investigators (PYI) aka residents, and interns.
 ADAPT: Actively Discovering and Adapting to Preferences for any Task.
ADAPT: Actively Discovering and Adapting to Preferences for any Task. PARTNR: A Benchmark for Planning and Reasoning in Embodied Multi-agent Tasks.
PARTNR: A Benchmark for Planning and Reasoning in Embodied Multi-agent Tasks. From an Image to a Scene: Learning to Imagine the World from a Million 360° Videos.
From an Image to a Scene: Learning to Imagine the World from a Million 360° Videos. Situated Instruction Following.
Situated Instruction Following. Track2Act: Predicting Point Tracks from Internet Videos enables Diverse Robot Manipulation.
Track2Act: Predicting Point Tracks from Internet Videos enables Diverse Robot Manipulation. Controllable Human-Object Interaction Synthesis.
Controllable Human-Object Interaction Synthesis. GOAT: GO to Any Thing.
GOAT: GO to Any Thing.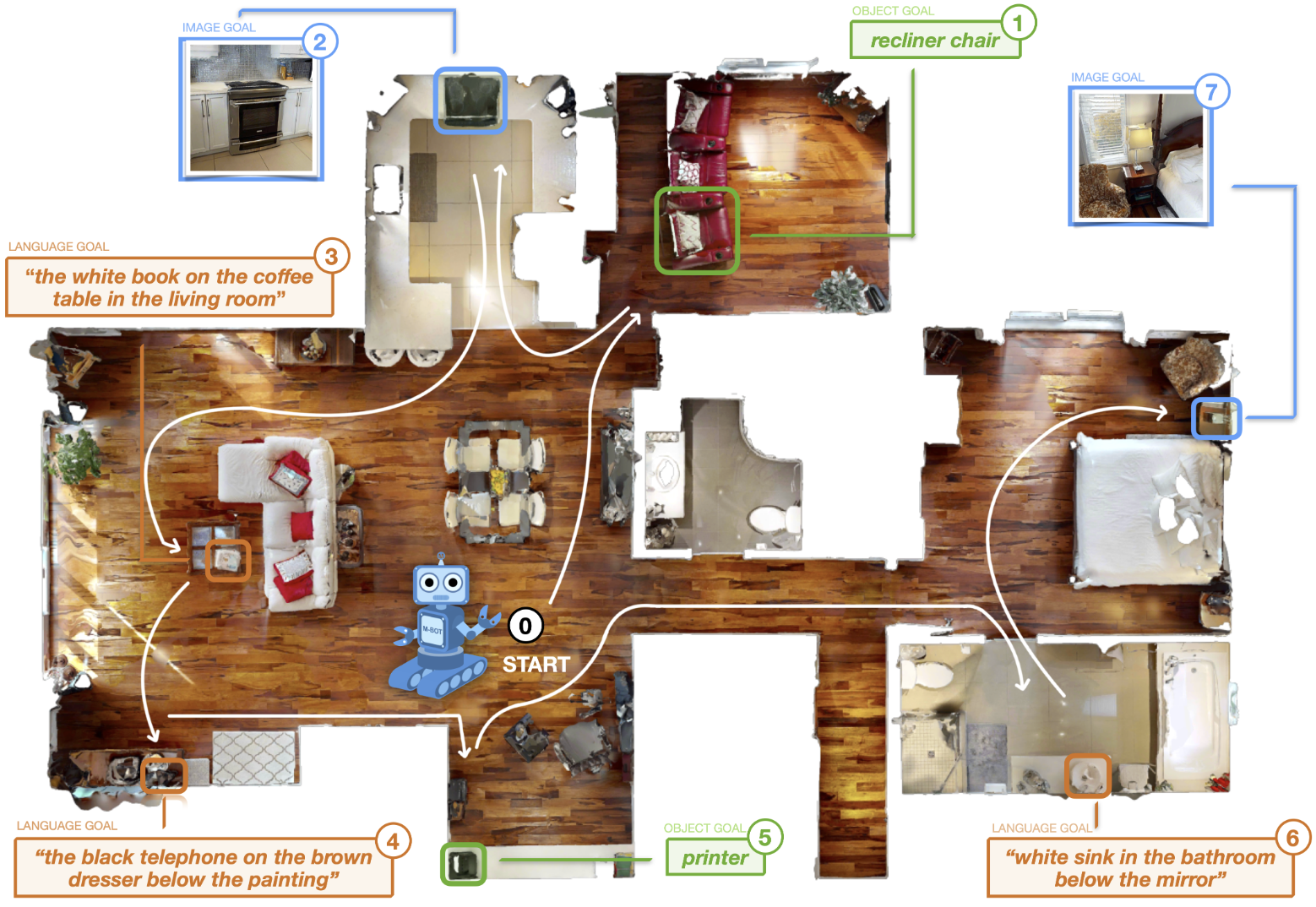 GOAT-Bench: A Benchmark for Multi-Modal Lifelong Navigation.
GOAT-Bench: A Benchmark for Multi-Modal Lifelong Navigation. Habitat 3.0: A Co-Habitat for Humans, Avatars and Robots.
Habitat 3.0: A Co-Habitat for Humans, Avatars and Robots.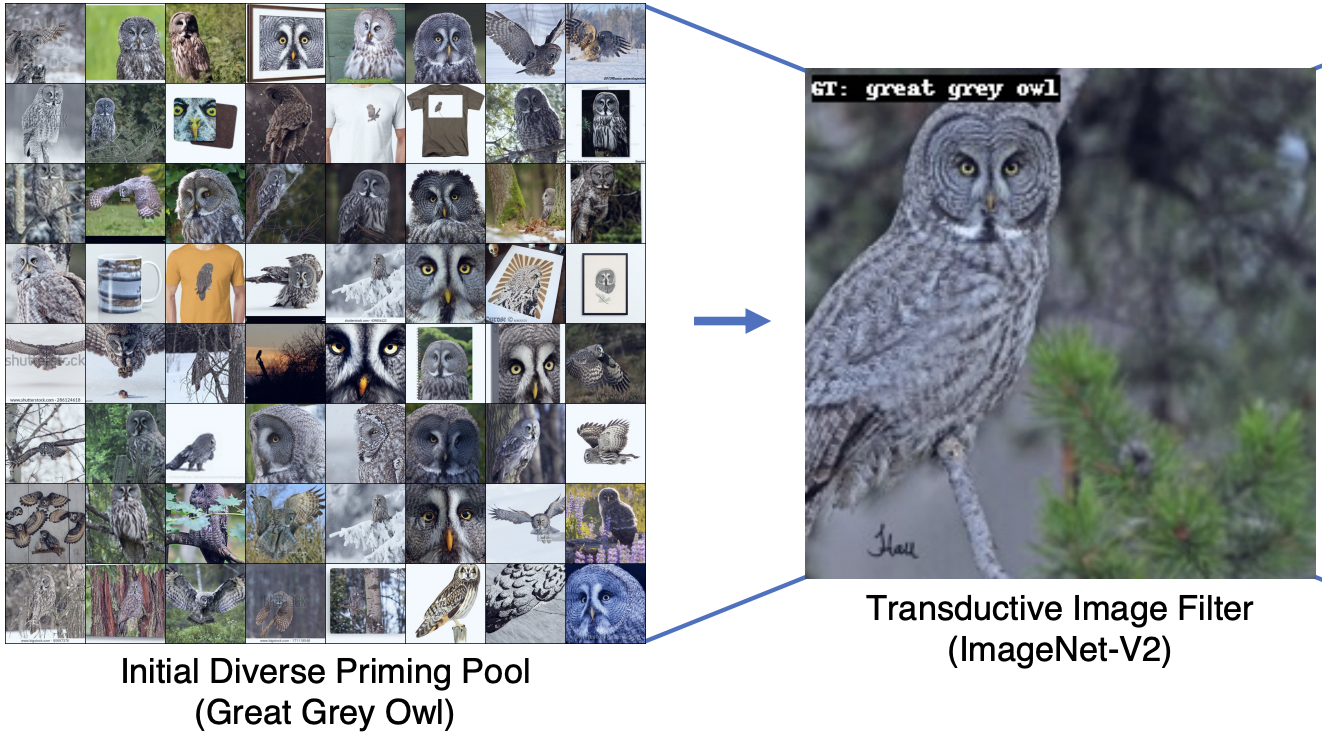 Neural Priming for Sample-Efficient Adaptation.
Neural Priming for Sample-Efficient Adaptation. HomeRobot: Open-Vocabulary Mobile Manipulation.
HomeRobot: Open-Vocabulary Mobile Manipulation. ENTL: Embodied Navigation Trajectory Learner.
ENTL: Embodied Navigation Trajectory Learner.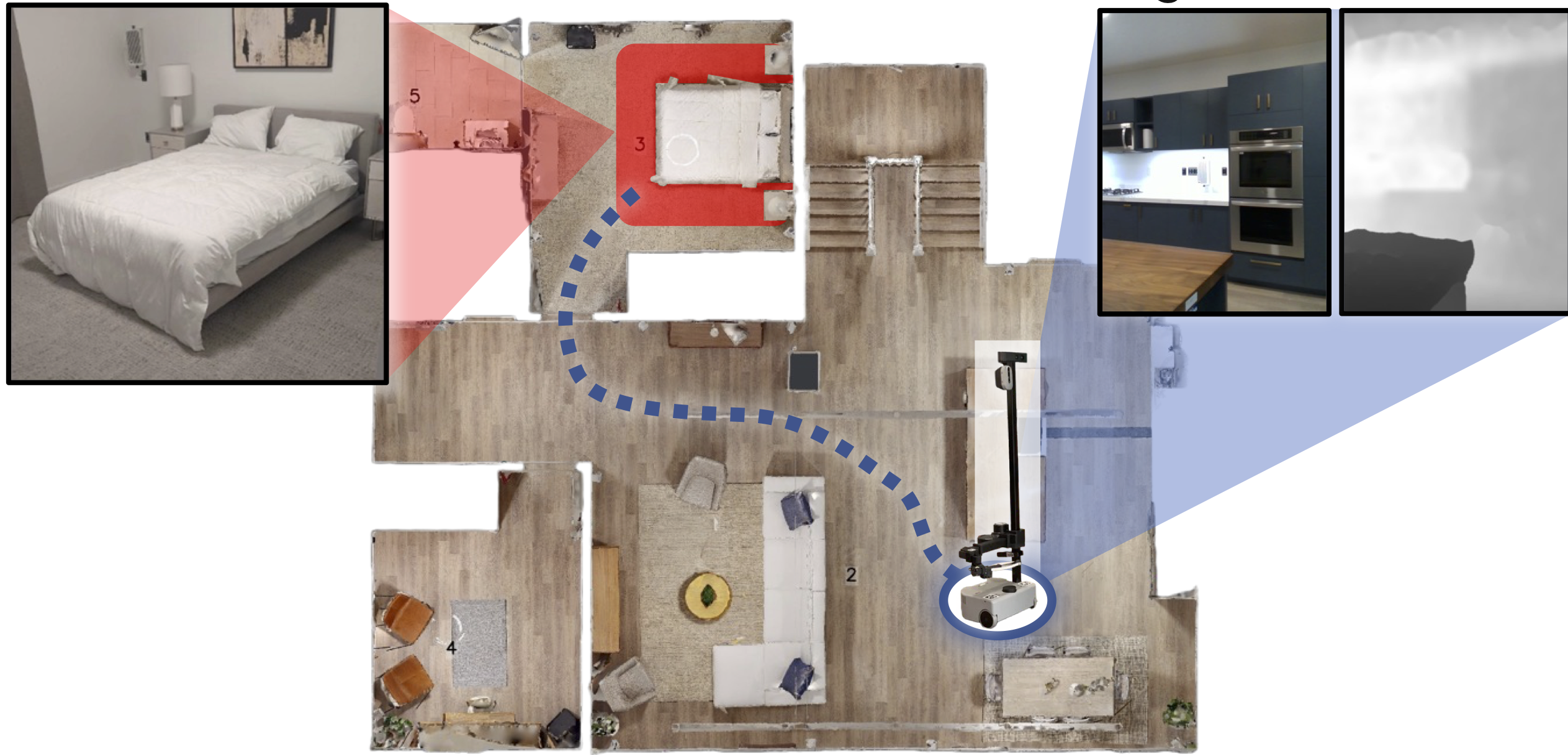 Navigating to Objects Specified by Images.
Navigating to Objects Specified by Images.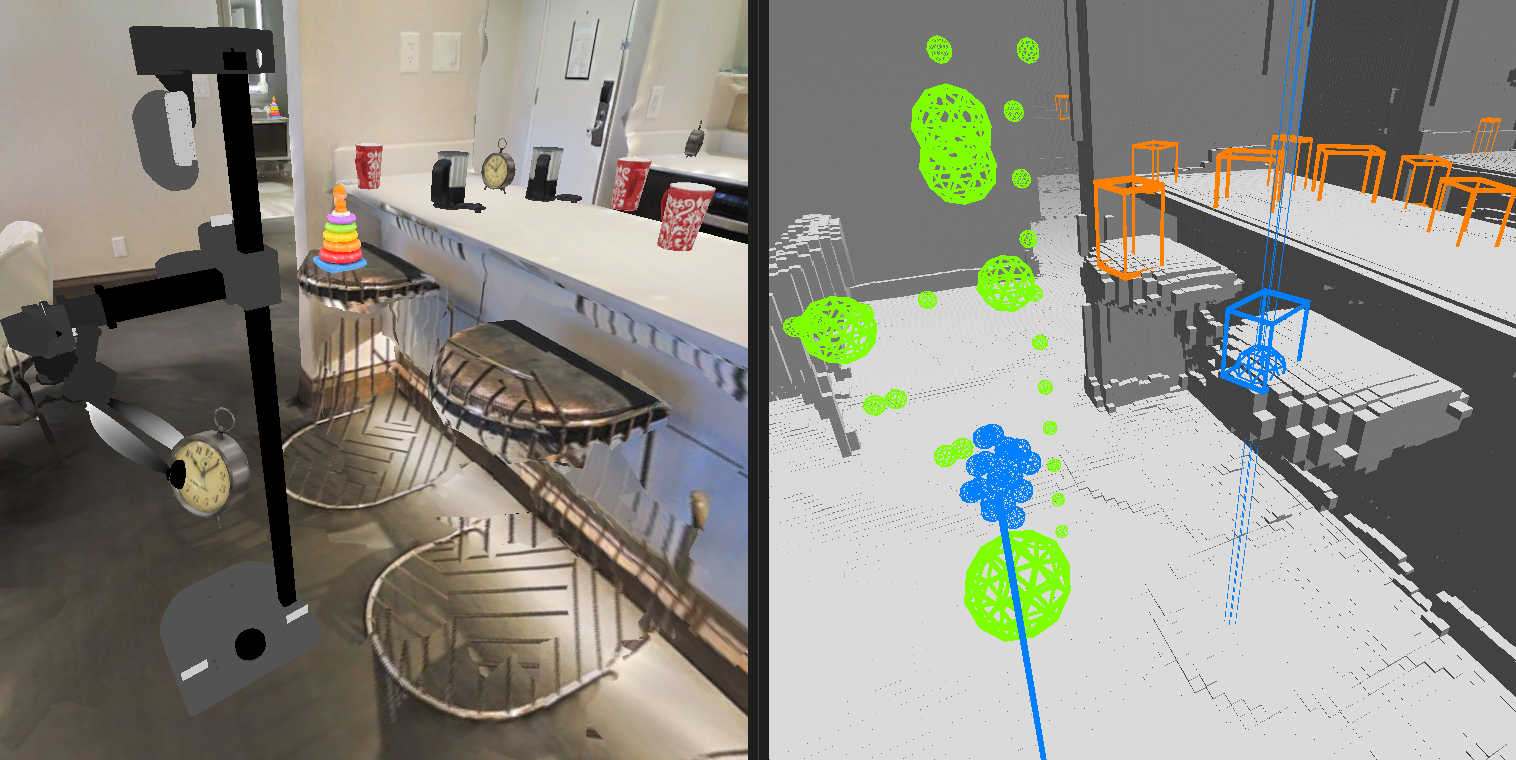 Galactic: Scaling End-to-End Reinforcement Learning for Rearrangement at 100k Steps-Per-Second.
Galactic: Scaling End-to-End Reinforcement Learning for Rearrangement at 100k Steps-Per-Second.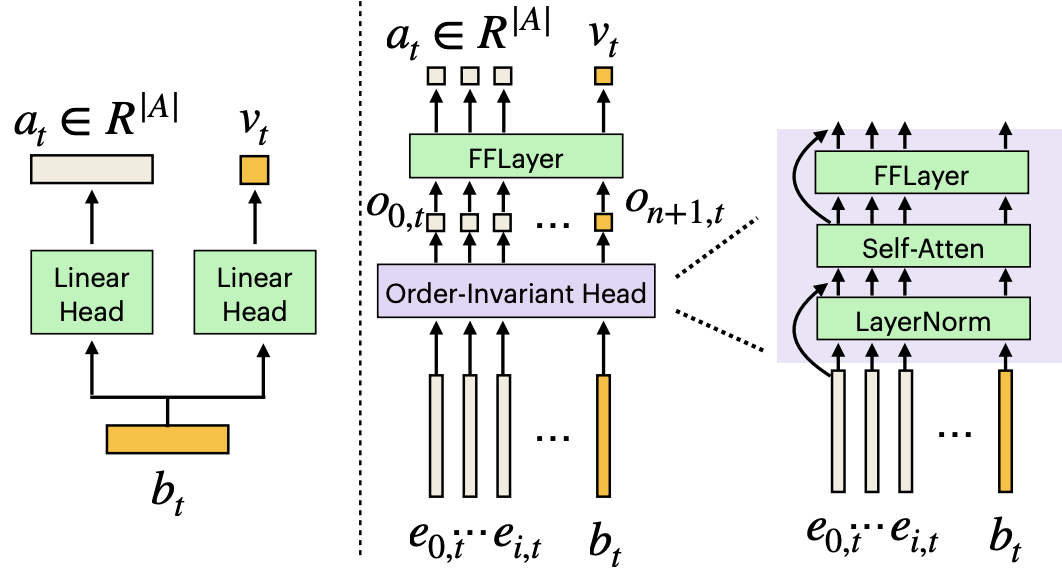 Moving Forward by Moving Backward: Embedding Action Impact over Action Semantics.
Moving Forward by Moving Backward: Embedding Action Impact over Action Semantics.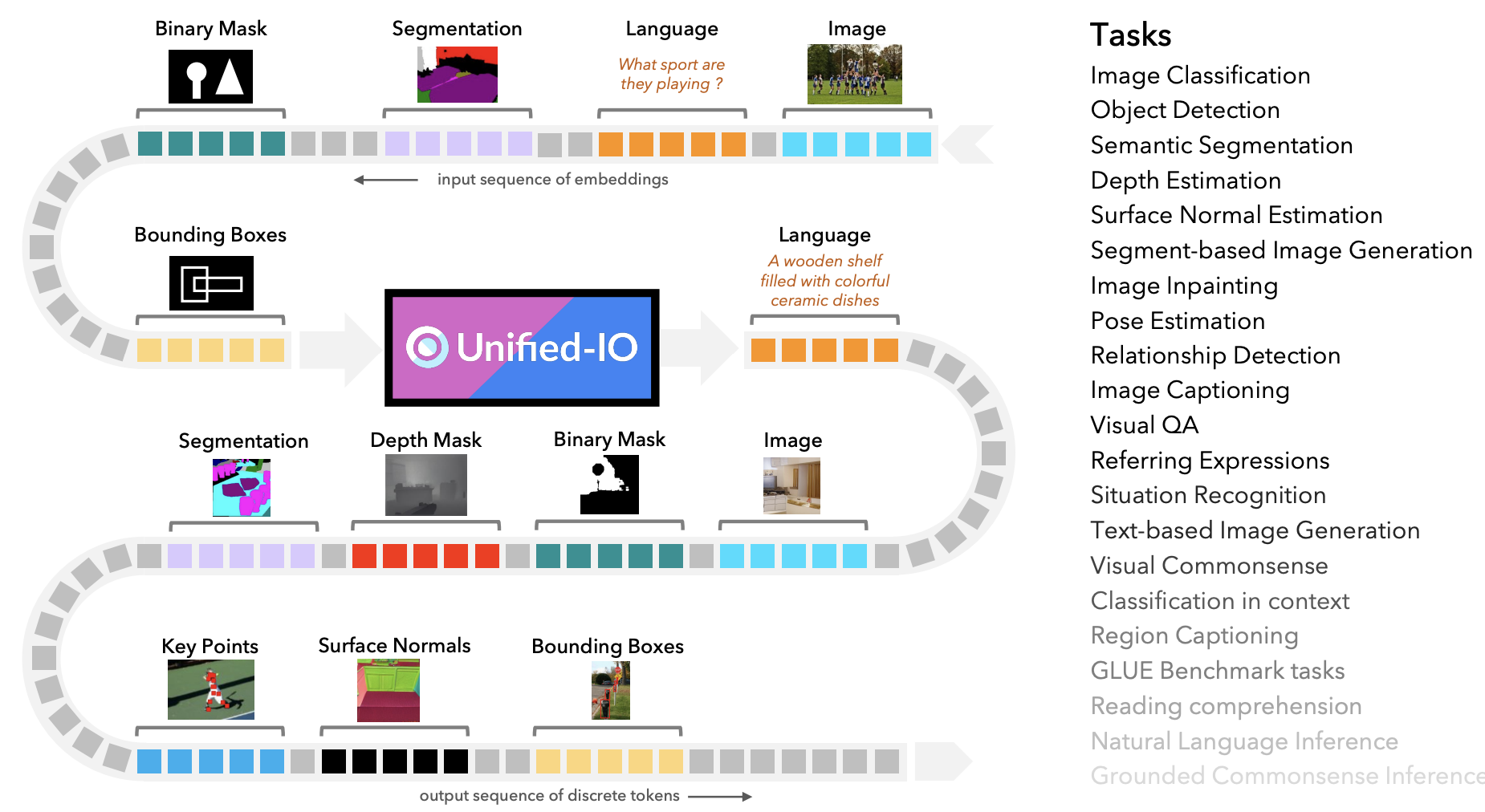 Unified-IO: A Unified Model for Vision, Language, and Multi-modal Tasks.
Unified-IO: A Unified Model for Vision, Language, and Multi-modal Tasks. Neural Radiance Field Codebooks.
Neural Radiance Field Codebooks. ProcTHOR: Large-Scale Embodied AI Using Procedural Generation.
ProcTHOR: Large-Scale Embodied AI Using Procedural Generation. Ask4Help: Learning to Leverage an Expert for Embodied Tasks.
Ask4Help: Learning to Leverage an Expert for Embodied Tasks. Benchmarking Progress to Infant-Level Physical Reasoning in AI.
Benchmarking Progress to Infant-Level Physical Reasoning in AI. A-OKVQA: A Benchmark for Visual Question Answering using World Knowledge.
A-OKVQA: A Benchmark for Visual Question Answering using World Knowledge. Object Manipulation via Visual Target Localization.
Object Manipulation via Visual Target Localization. Interactron: Embodied Adaptive Object Detection.
Interactron: Embodied Adaptive Object Detection. Continuous Scene Representations for Embodied AI.
Continuous Scene Representations for Embodied AI. What do navigation agents learn about their environment?
What do navigation agents learn about their environment?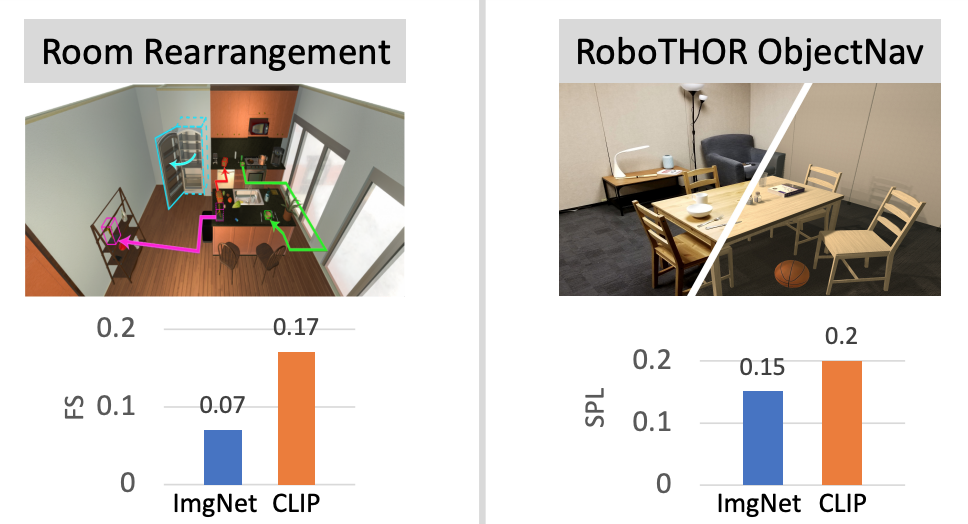 Simple but Effective: CLIP Embeddings for Embodied AI.
Simple but Effective: CLIP Embeddings for Embodied AI. Multi-Modal Answer Validation for Knowledge-Based VQA.
Multi-Modal Answer Validation for Knowledge-Based VQA. Container: Context Aggregation Networks.
Container: Context Aggregation Networks.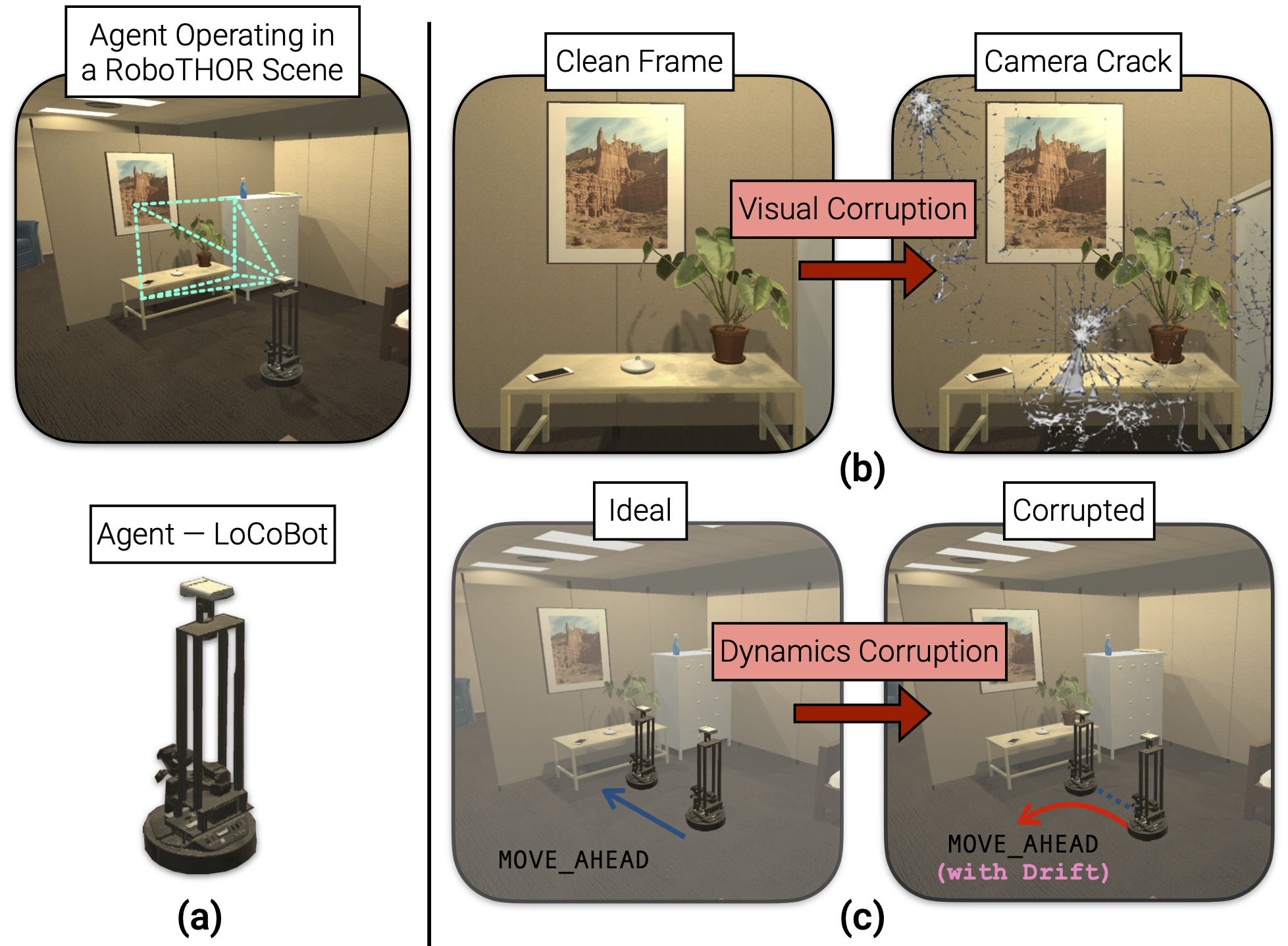 RobustNav : Towards Benchmarking Robustness in Embodied Navigation.
RobustNav : Towards Benchmarking Robustness in Embodied Navigation.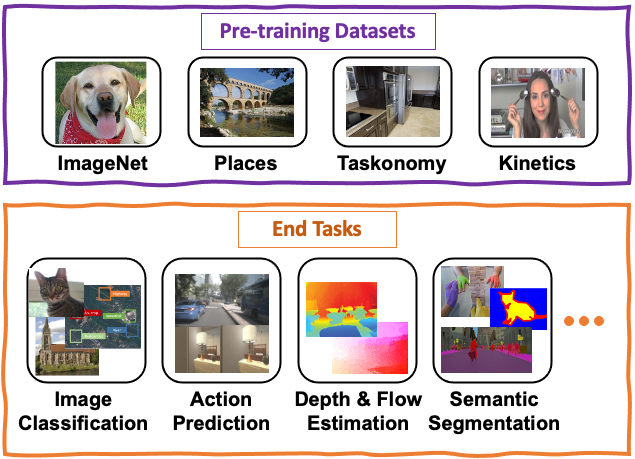 Contrasting Contrastive Self-Supervised Representation Learning Pipelines.
Contrasting Contrastive Self-Supervised Representation Learning Pipelines.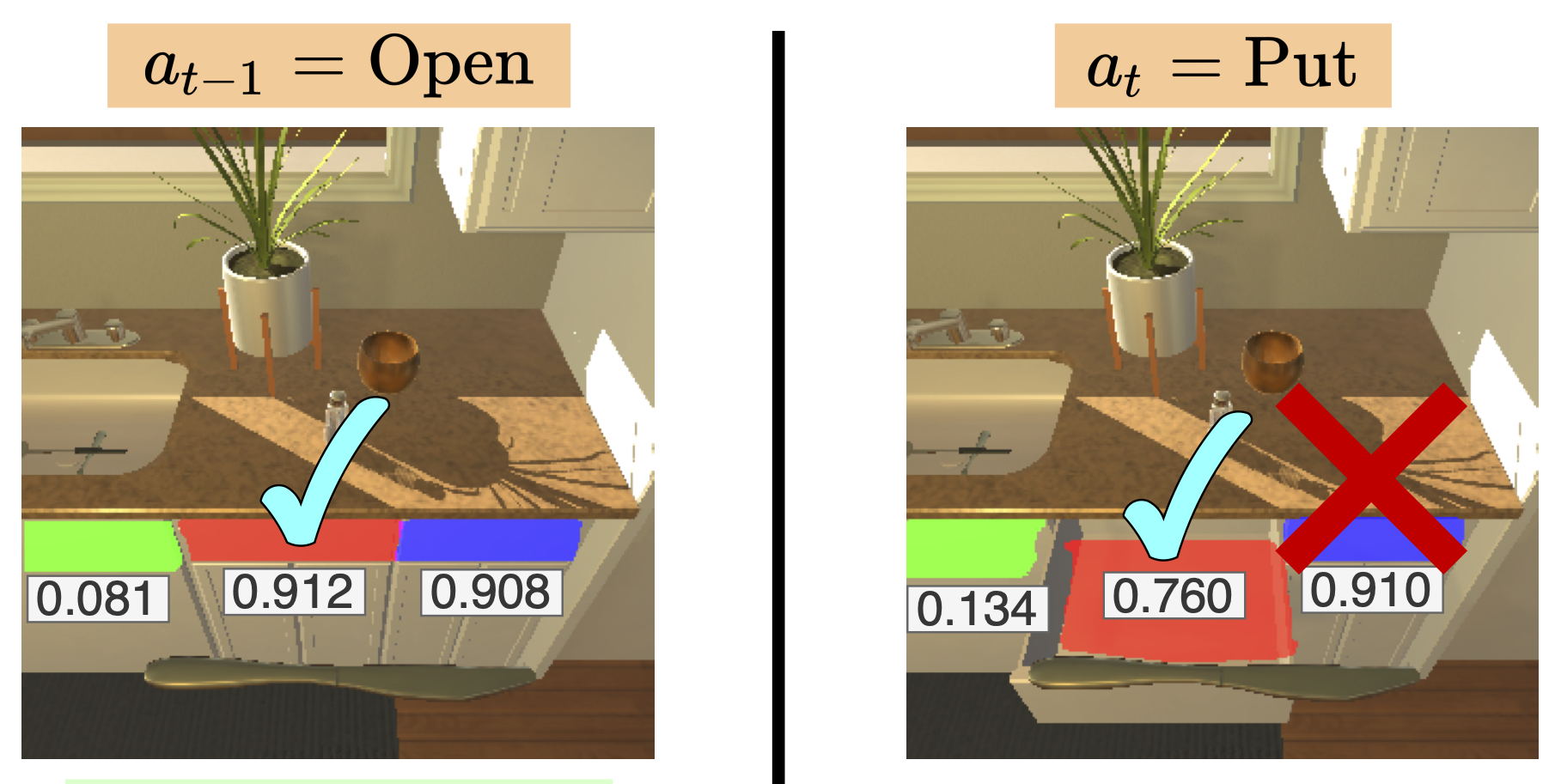 Factorizing Perception and Policy for Interactive Instruction Following.
Factorizing Perception and Policy for Interactive Instruction Following.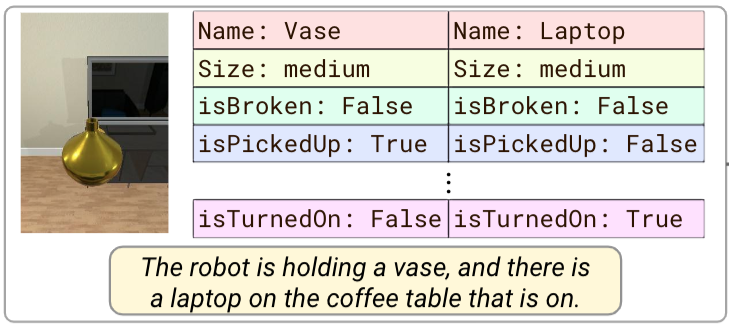 PIGLeT: Language Grounding Through Neuro-Symbolic Interaction in a 3D World.
PIGLeT: Language Grounding Through Neuro-Symbolic Interaction in a 3D World.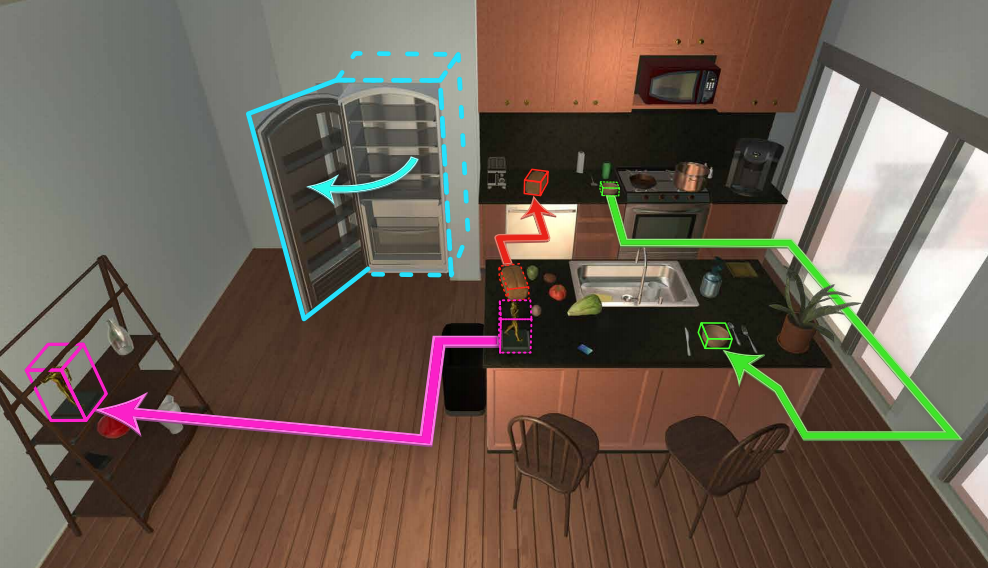 Visual Room Rearrangement.
Visual Room Rearrangement. ManipulaTHOR: A Framework for Visual Object Manipulation.
ManipulaTHOR: A Framework for Visual Object Manipulation. Pushing it out of the Way: Interactive Visual Navigation.
Pushing it out of the Way: Interactive Visual Navigation. Learning Generalizable Visual Representations via Interactive Gameplay.
Learning Generalizable Visual Representations via Interactive Gameplay. What Can You Learn from Your Muscles? Learning Visual Representation from Human Interactions.
What Can You Learn from Your Muscles? Learning Visual Representation from Human Interactions. Rearrangement: A Challenge for Embodied AI.
Rearrangement: A Challenge for Embodied AI. Learning About Objects by Learning to Interact with Them.
Learning About Objects by Learning to Interact with Them. AllenAct: A Framework for Embodied AI Research.
AllenAct: A Framework for Embodied AI Research.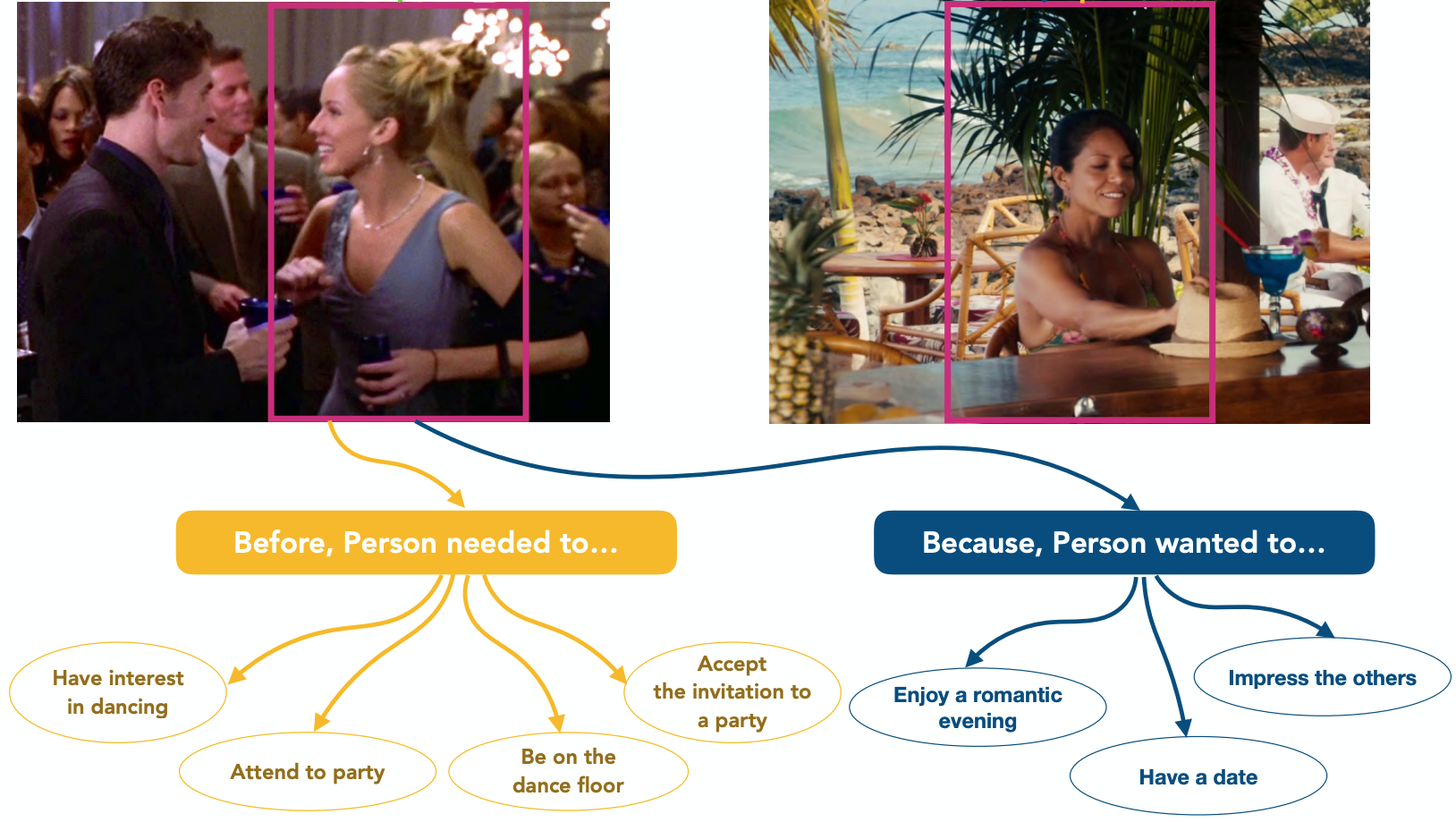 Visual Commonsense Graphs: Reasoning about the Dynamic Context of a Still Image.
Visual Commonsense Graphs: Reasoning about the Dynamic Context of a Still Image.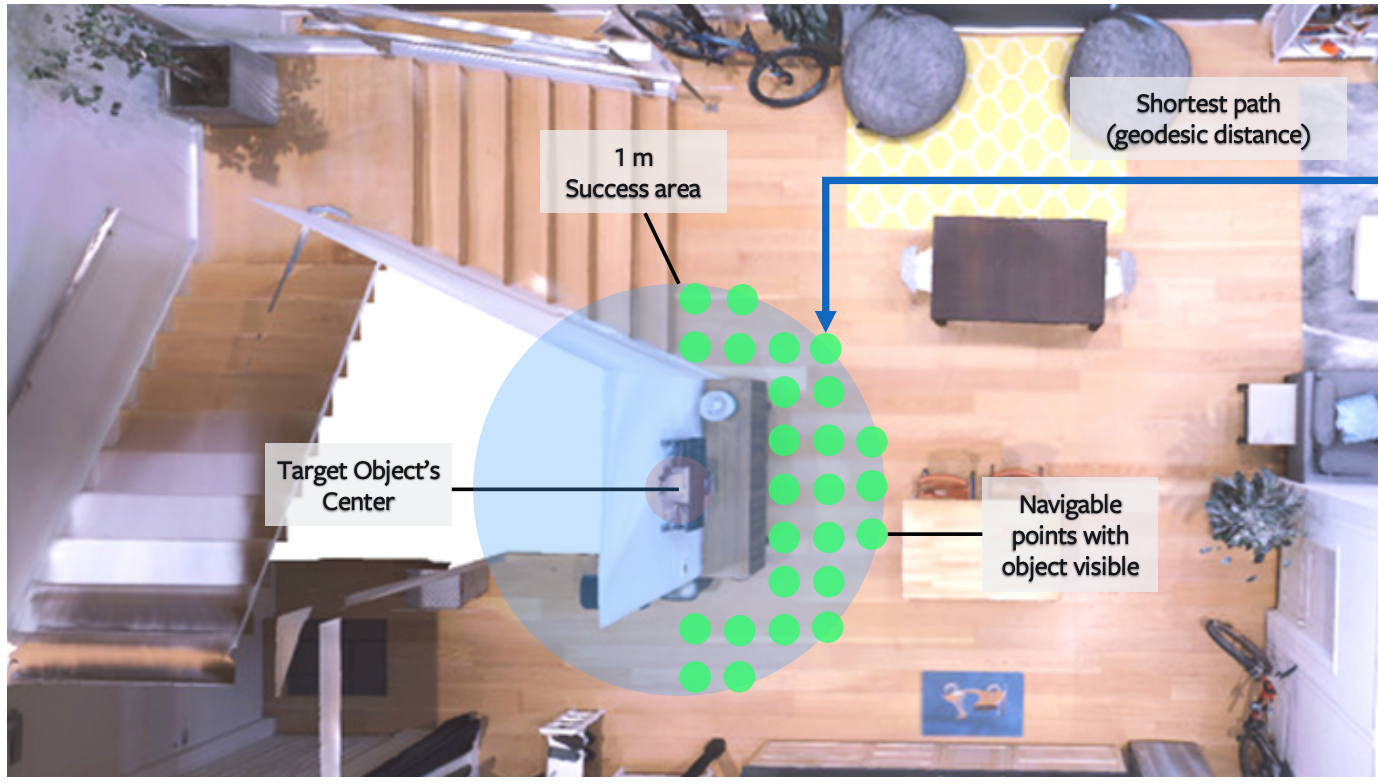 ObjectNav Revisited: On Evaluation of Embodied Agents Navigating to Objects.
ObjectNav Revisited: On Evaluation of Embodied Agents Navigating to Objects. RoboTHOR: An Open Simulation-to-Real Embodied AI Platform.
RoboTHOR: An Open Simulation-to-Real Embodied AI Platform.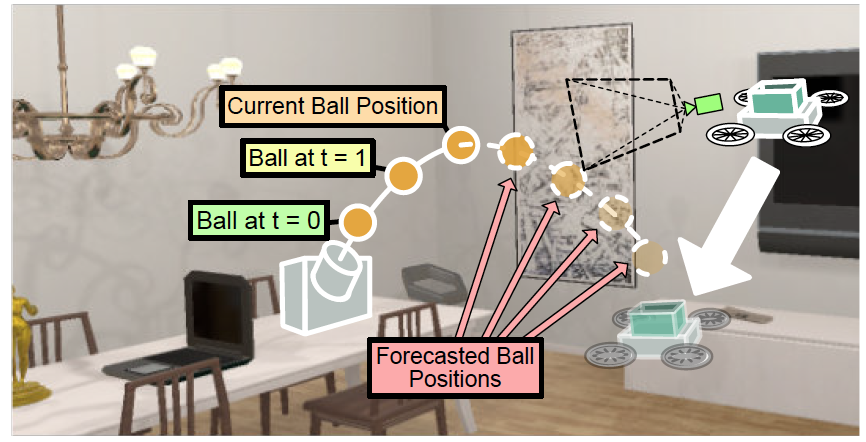 Visual Reaction: Learning To Play Catch With Your Drone.
Visual Reaction: Learning To Play Catch With Your Drone.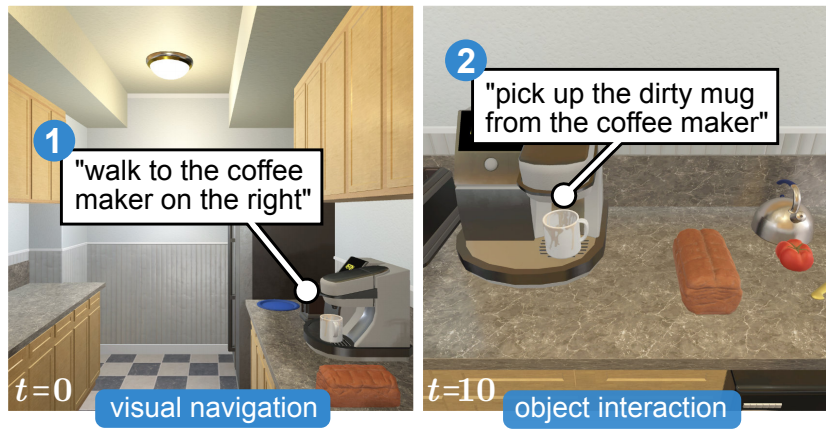 ALFRED: A Benchmark for Interpreting Grounded Instructions for Everyday Tasks.
ALFRED: A Benchmark for Interpreting Grounded Instructions for Everyday Tasks.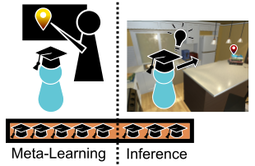 Learning to Learn How to Learn: Self-Adaptive Visual Navigation using Meta-Learning.
Learning to Learn How to Learn: Self-Adaptive Visual Navigation using Meta-Learning. OK-VQA: A Visual Question Answering Benchmark Requiring External Knowledge.
OK-VQA: A Visual Question Answering Benchmark Requiring External Knowledge.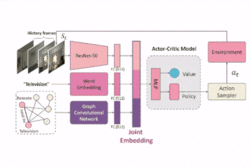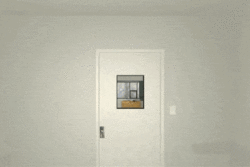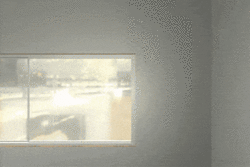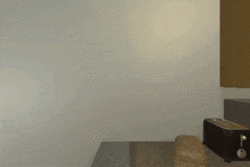 Visual Semantic Navigation using Scene Priors.
Visual Semantic Navigation using Scene Priors. On Evaluation of Embodied Navigation Agents.
On Evaluation of Embodied Navigation Agents. Who Let The Dogs Out? Modeling Dog Behavior From Visual Data.
Who Let The Dogs Out? Modeling Dog Behavior From Visual Data. SeGAN: Segmenting and Generating the Invisible.
SeGAN: Segmenting and Generating the Invisible. AI2-THOR: An Interactive 3D Environment for Visual AI.
AI2-THOR: An Interactive 3D Environment for Visual AI. Visual Semantic Planning using Deep Successor Representations.
Visual Semantic Planning using Deep Successor Representations. See the Glass Half Full: Reasoning about Liquid Containers, their Volume and Content.
See the Glass Half Full: Reasoning about Liquid Containers, their Volume and Content. Target-driven Visual Navigation in Indoor Scenes using Deep Reinforcement Learning.
Target-driven Visual Navigation in Indoor Scenes using Deep Reinforcement Learning. "What happens if..." Learning to Predict the Effect of Forces in Images.
"What happens if..." Learning to Predict the Effect of Forces in Images. ObjectNet3D: A Large Scale Database for 3D Object Recognition.
ObjectNet3D: A Large Scale Database for 3D Object Recognition.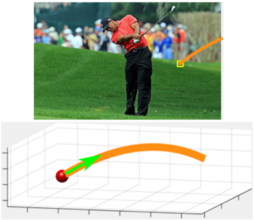 Newtonian Image Understanding: Unfolding the Dynamics of Objects in Static Images.
Newtonian Image Understanding: Unfolding the Dynamics of Objects in Static Images.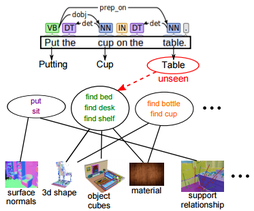 A Task-oriented Approach for Cost-sensitive Recognition.
A Task-oriented Approach for Cost-sensitive Recognition.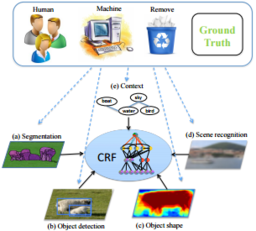 Human-Machine CRFs for Identifying Bottlenecks in Scene Understanding.
Human-Machine CRFs for Identifying Bottlenecks in Scene Understanding.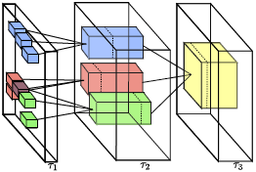 Complexity of Representation and Inference in Compositional Models with Part Sharing.
Complexity of Representation and Inference in Compositional Models with Part Sharing.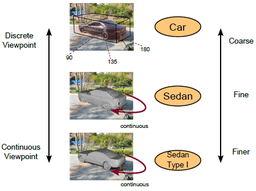 A Coarse-to-Fine Model for 3D Pose Estimation and Sub-category Recognition.
A Coarse-to-Fine Model for 3D Pose Estimation and Sub-category Recognition.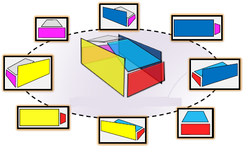 Monocular Multiview Object Tracking with 3D Aspect Parts.
Monocular Multiview Object Tracking with 3D Aspect Parts. Beyond PASCAL: A Benchmark for 3D Object Detection in the Wild.
Beyond PASCAL: A Benchmark for 3D Object Detection in the Wild. The Role of Context for Object Detection and Semantic Segmentation in the Wild.
The Role of Context for Object Detection and Semantic Segmentation in the Wild. Detect What You Can: Detecting and Representing Objects using Holistic Models and Body Parts.
Detect What You Can: Detecting and Representing Objects using Holistic Models and Body Parts. Complexity of Representation and Inference in Compositional Models with Part Sharing.
Complexity of Representation and Inference in Compositional Models with Part Sharing. Analyzing Semantic Segmentation Using Hybrid Human-Machine CRFs.
Analyzing Semantic Segmentation Using Hybrid Human-Machine CRFs. Bottom-up Segmentation for Top-down Detection.
Bottom-up Segmentation for Top-down Detection. Augmenting Deformable Part Models with Irregular-shaped Object Patches.
Augmenting Deformable Part Models with Irregular-shaped Object Patches. A Compositional Approach to Learning Part-based Models of Objects.
A Compositional Approach to Learning Part-based Models of Objects. Graph-based Planning Using Local Information for Unknown Outdoor Environments.
Graph-based Planning Using Local Information for Unknown Outdoor Environments. Place Recognition-based Fixed-lag Smoothing for Environments with Unreliable GPS.
Place Recognition-based Fixed-lag Smoothing for Environments with Unreliable GPS. An Integrated Particle Filter and Potential Field Method Applied to Multi-Robot Target Tracking.
An Integrated Particle Filter and Potential Field Method Applied to Multi-Robot Target Tracking. An Integrated Particle Filter & Potential Field Method for Cooperative Robot Target Tracking.
An Integrated Particle Filter & Potential Field Method for Cooperative Robot Target Tracking. An Overview of a Probabilistic Tracker for Multiple Cooperative Tracking Agents.
An Overview of a Probabilistic Tracker for Multiple Cooperative Tracking Agents. Coordination of Multiple Agents for Probabilistic Object Tracking.
Coordination of Multiple Agents for Probabilistic Object Tracking. SharifCESR Small Size Robocup Team.
SharifCESR Small Size Robocup Team.|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|